
サポートベクトルマシンとは、複数のサンプルデータを2つのクラスに分類する手法です。各データ点との距離が最大になる超平面を求める問題として、パラメタが学習されます。
空間内の点の分類
$D$ 次元空間の $N$ 個の点 ${\bf x}_n$ を2つのクラスに分類する問題を考えます。$D$ 次元空間を仕切るためには、次の超平面のパラメタ $a_1\sim a_D,b$ を求める必要があります。
$$a_1x_1+a_2x_2+\cdots+a_Dx_D+b=0$$
ここで、次の関数を定義し、
$$y({\bf x})=a_1x_1+a_2x_2+\cdots+a_Dx_D+b={\bf a}\cdot{\bf x}+b$$
全ての点が、超平面のどちらかの側に分類された場合、目的変数 $t_n$ を次のように定義すると、
- クラス1:
$y({\bf x}_n)\gt0$ ならば $t_n=1$ - クラス2:
$y({\bf x}_n)\lt0$ ならば $t_n=-1$
常に、$t_ny({\bf x}_n)\gt0$ であることが分かります。このことを利用すると、点 ${\bf x}_n$ と超平面との距離 $d$ は以下で求められるため、
$$d=\frac{|{\bf a}\cdot{\bf x}_n+b|}{|{\bf a}|}=\frac{t_n({\bf a}\cdot{\bf x}_n+b)}{|{\bf a}|} -①$$
超平面に最も近い点 ${\bf x}_n$ について、その距離(マージン)が最大になるような超平面($a_1\sim a_D,b$)を求める問題に帰着します。これを式で表すと以下になります。
$$\max_{{\bf a},b}\left(\frac{1}{|{\bf a}|}\min_n\Big[t_n({\bf a}\cdot{\bf x}_n+b)\Big]\right) -②$$
2次元の場合
①を分かりやすく2次元($D=2$)で考えると、各点を仕切る超平面は直線として表されます。一般に、ある点($x_1,y_1$)と直線 $ax+by+c=0$ の距離は以下で表されます。
$$d=\frac{|ax_1+by_1+c|}{\sqrt{a^2+b^2}}$$
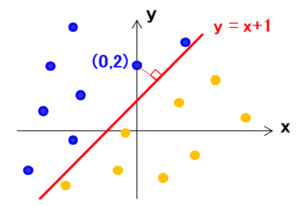
例えば、点(0、2)と直線 $y=x+1$ との距離は $d=1/\sqrt{2}$ となります。
問題の簡略化
②の解くことは複雑であるため、ラグランジュ未定乗数法を利用して、問題の簡略化を図ります。距離①は、超平面の係数(${\bf a},b$)を定数倍しても変わらないため、
$$t_n({\bf a}\cdot{\bf x}_n+b)=1 -③$$
とういう条件を置けば、この条件のもとで、以下の関数を最大にすればよいことになります。
$$\max_{{\bf a},b}\frac{1}{|{\bf a}|}$$
さらに、これを最大ということは、$|{\bf a}|^2$ を最小化することなので、③の条件の下で、以下の関数を最小化する問題と等価になります。
$$\min_{{\bf a},b}\frac{1}{2}|{\bf a}|^2 -④$$
ここで、ラグランジュ未定乗数法を利用すると、次のラグランジュ関数($\lambda_n\ge0$)が、
$$L({\bf a},b,\lambda_n)=\frac{1}{2}|{\bf a}|^2-\sum_{n=1}^N\lambda_n\Big[t_n({\bf a}\cdot{\bf x}_n+b)-1\Big] -⑤$$
停留値を取る(${\bf a},b$)を求めればよいことになります。この停留値を取る条件は以下で表されます。
$$\frac{\partial L}{\partial{\bf a}}={\bf a}-\sum_{n=1}^N\lambda_nt_n{\bf x}_n=0 -⑥$$$$\frac{\partial L}{\partial b}=-\sum_{n=1}^N\lambda_nt_n=0 -⑦$$
双対表現
双対表現とは、⑥を⑤に代入して得られる次のラグランジュ関数のことです。
$$\tilde{L}(\lambda_n)=\sum_{n=1}^N\lambda_n-\frac{1}{2}\sum_{n,m=1}^N\lambda_n\lambda_mt_nt_mk({\bf x}_n,{\bf x}_m) -⑧$$
ここで、$k$ はカーネル関数と呼ばれており、以下で一般に定義されます。
$$k({\bf x}_n,{\bf x}_m)\equiv\phi({\bf x})^t\phi({\bf x})={\bf x}_n\cdot{\bf x}_m -⑨$$
尚、制約条件は以下になります。
$$\frac{\partial L}{\partial b}=-\sum_{n=1}^N\lambda_nt_n=0$$$$\lambda_n\ge0$$
⑧を導く
⑥を⑤に代入すると、
$$L=\frac{1}{2}\Big(\sum_{m=1}^M\lambda_mt_m{\bf x}_m\Big)\cdot\Big(\sum_{n=1}^N\lambda_nt_n{\bf x}_n\Big)$$$$-\Big(\sum_{m=1}^M\lambda_mt_m{\bf x}_m\Big)\cdot\Big(\sum_{n=1}^N\lambda_nt_n{\bf x}_n\Big)-\sum_{n=1}^N\lambda_n(t_nb-1)$$$$=-\frac{1}{2}\sum_{m=1}^M\sum_{n=1}^N\lambda_m\lambda_nt_mt_n({\bf x}_m\cdot {\bf x}_n)+\sum_{n=1}^N\lambda_n$$
最後の項は⑦を利用しています。一般形として⑨の $k({\bf x}_n,{\bf x}_m)$ を導入すると、⑧が得られることが分かります。



